Uncover Insights on the Public's Opinion of Measles from Twitter
Harness Melax Tech's NLP, deep learning, and multi-task learning to gain insights about the public’s opinion of measles from Twitter.


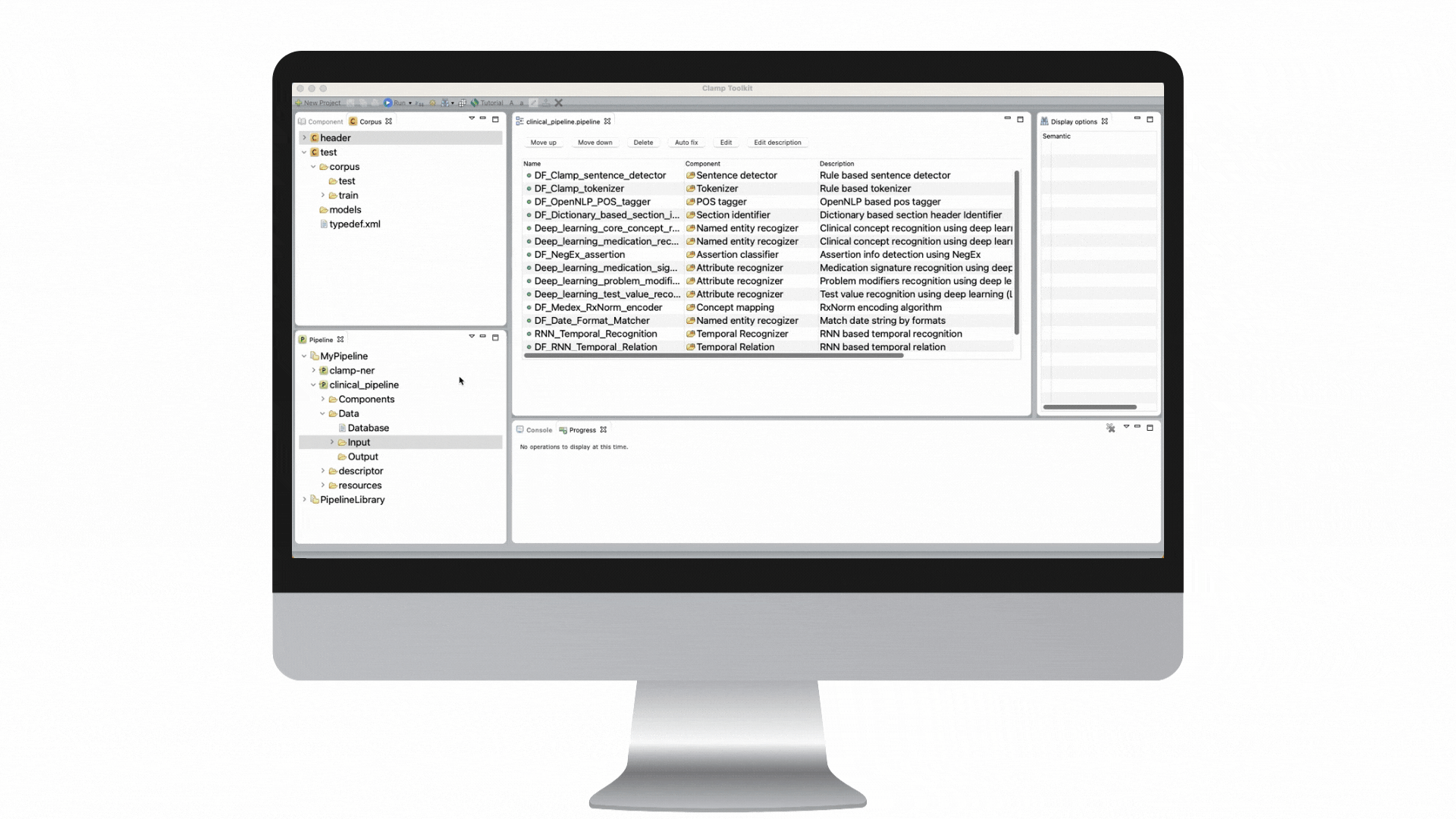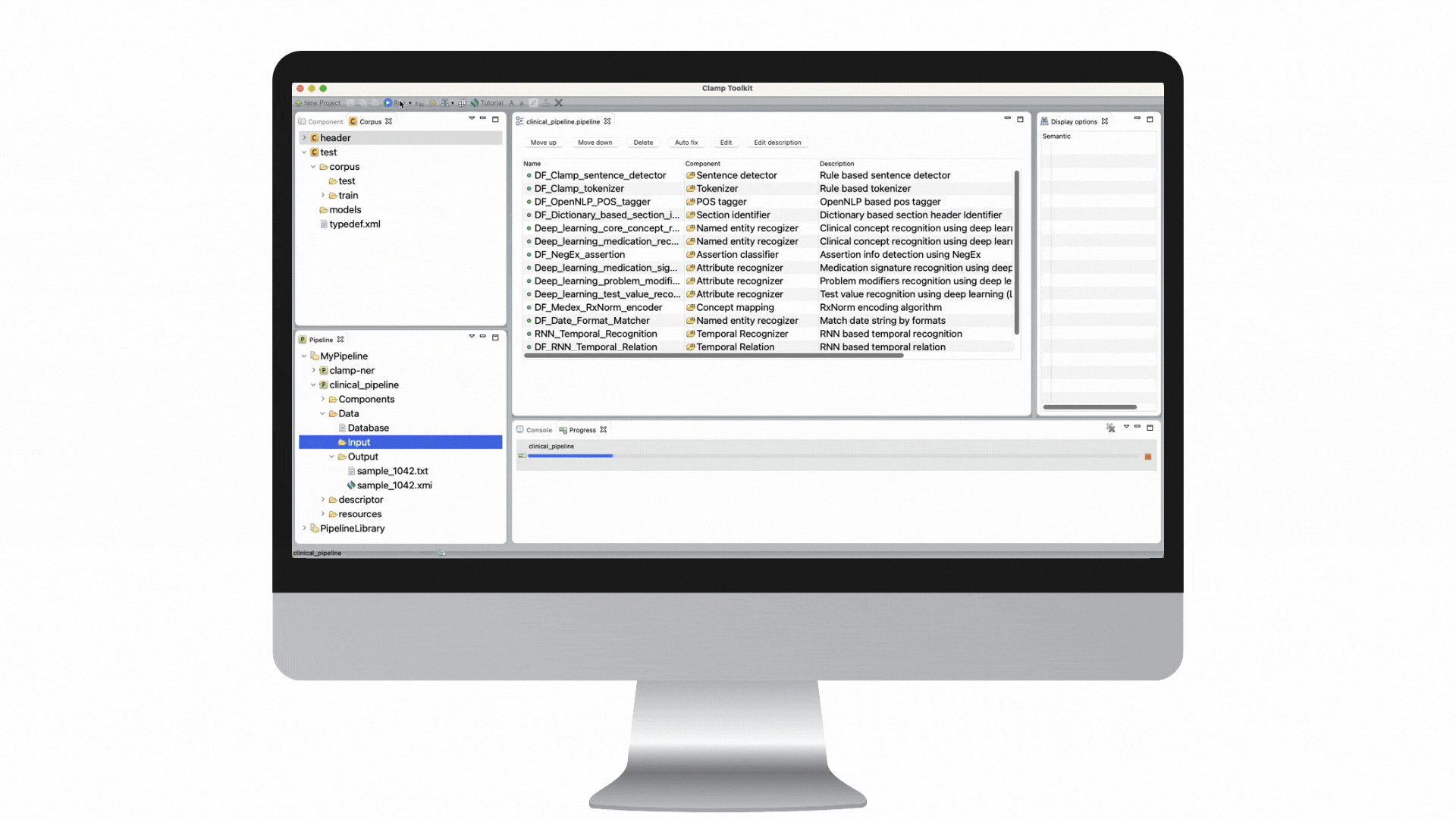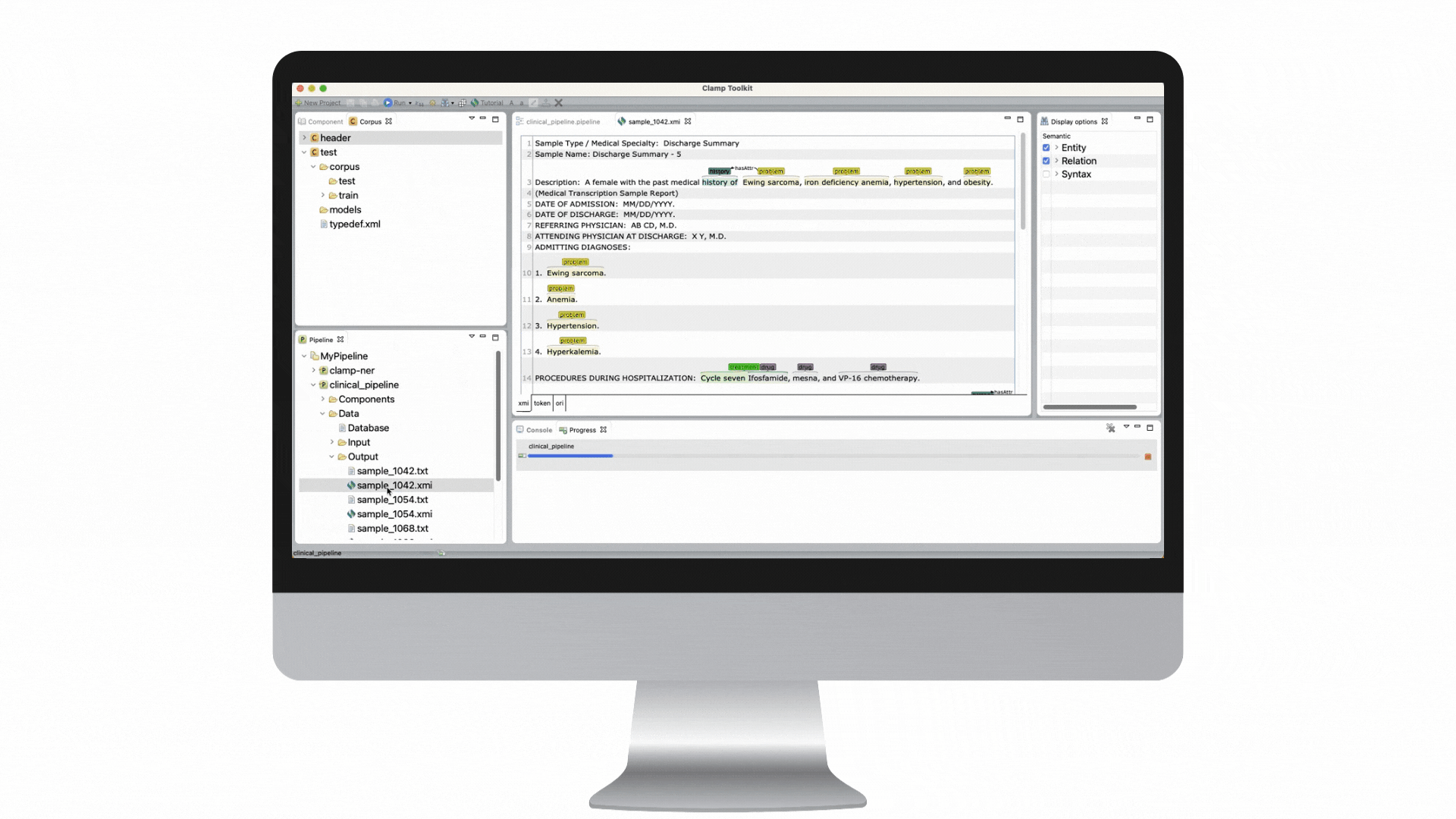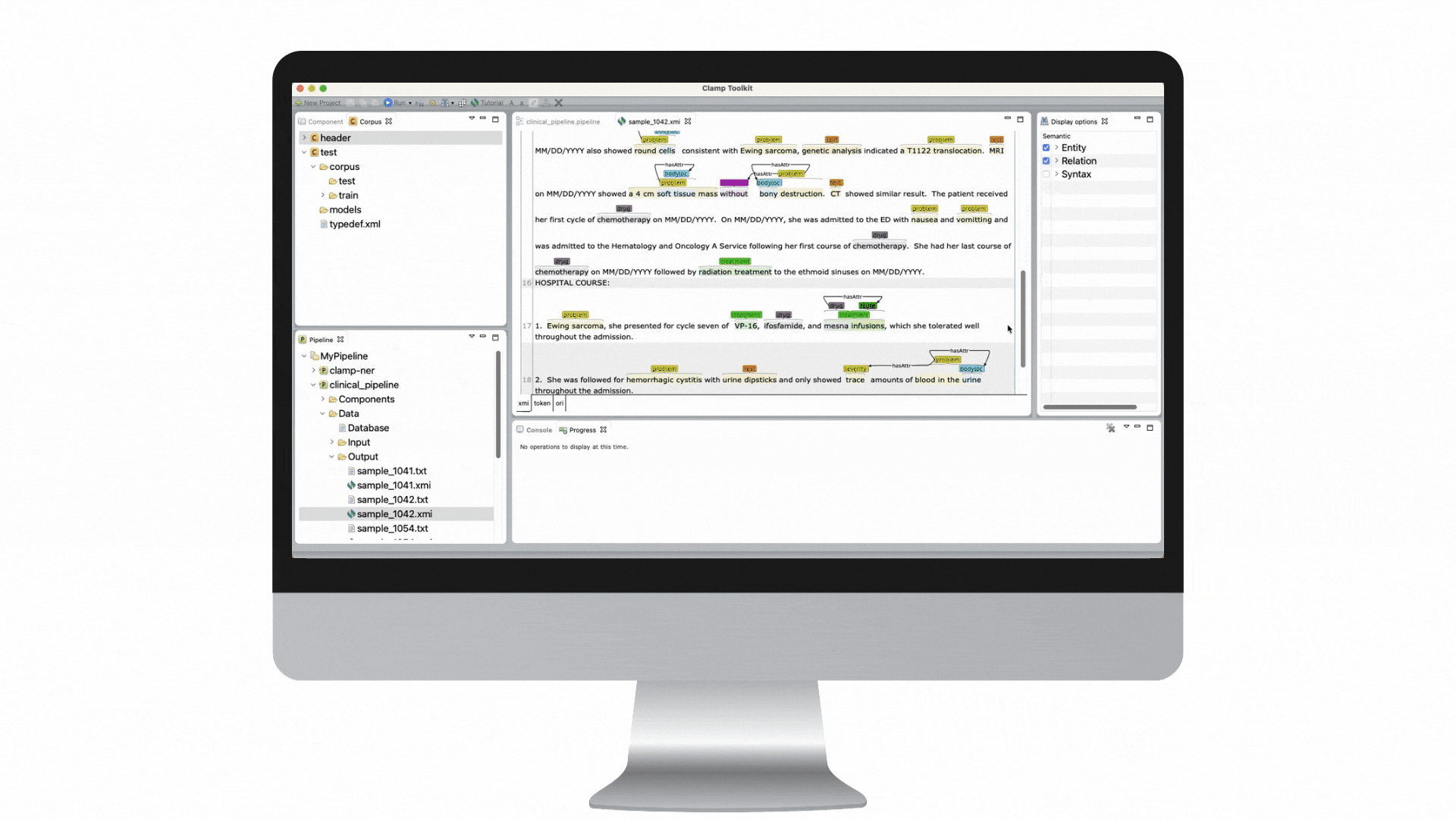
Our clinical language annotation, modeling, and processing toolkit is an AI-powered environment where you can develop and engineer clinical NLP models. With CLAMP, you can easily recognize and automatically encode clinical information to improve patient outcomes.
Ranked #1 in multiple head-to-head contests & Google search for “clinical NLP tool”
Award-winning algorithms + GUIs for building a customized solution
2.5 user community (and growing)







